
RANJITH MAHESH
KI-Softwareentwickler (Data Science & ML) | M.Sc. Digital Engineering
👋 Über mich
🚀 KI-Softwareentwickler, der End-to-End-KI-Produkte entwickelt – LLM/RAG-Systeme, ML-Pipelines und produktionsreife Webanwendungen – mit starkem Fokus auf Datenqualität und Deployability.🎓 Ich studiere derzeit meinen M.Sc. Digital Engineering an der Otto-von-Guericke-Universität Magdeburg mit Schwerpunkt datengetriebene Ingenieurwissenschaft, Machine Learning und skalierbare KI-Systeme.🧪 Als Werkstudent in F&E / Technologische Innovation bei NgC GmbH entwickle ich interne Webprodukte (Python/Flask + HTML/CSS/JavaScript) und integriere KI in reale Workflows, einschließlich LLM/RAG-Komponenten (LangChain) und Retrieval mit PostgreSQL + pgvector.🛠️ Ich übernehme gerne den gesamten Lifecycle: Problemverständnis, Datenaufbereitung, Modellentwicklung, Backend-Integration, Evaluierung und Bereitstellung nutzbarer Interfaces.🏢 Zuvor verbrachte ich 2,5+ Jahre bei Accenture mit datenintensiven ERP-Workflows für einen Banking/ATM-Technologie-Kunden – Datenvalidierung, Migration/Konvertierung, Automatisierung und Reporting (Oracle SQL/PLSQL, Power BI) – was meine Fähigkeit stärkte, Produktionsergebnisse mit Stakeholdern zu liefern.
💡Fähigkeiten

KI/GenAI: LLM-Anwendungen, RAG, LangChain, pgvector (PostgreSQL Vector-Suche)ML/Data Science: scikit-learn, XGBoost, PyTorch, TensorFlow; Zeitreihenprognosen; Erklärbarkeit (LIME, Integrated Gradients, Permutation Importance)Backend/Web: Python, Flask, REST-APIs; HTML/CSS/JavaScriptDaten/Datenbanken: SQL; PostgreSQL, SQLiteCloud/MLOps: GCP, BigQuery, Kubeflow; Docker; GitBI: Looker Studio, Power BISprachen: Englisch (C1), Deutsch (B2)
🌟 Ausgewählte Projekte
Mastergrad-Projekte mit fortgeschrittenen Methoden zur Lösung realer Probleme – Forschung, Implementierung, Evaluierung.
🛠️ Bachelor-Projekte
Praxisnahe Projekte und Abschlussarbeiten im Maschinenbau (Fahrzeugtechnik) mit Fokus auf Konstruktion, Analyse und technische Dokumentation.
🌟 Ausgewählte Projekte

FMEA KNOWLEDGE REUSE (Masterarbeit)
Als Teil meiner Masterarbeit habe ich einen webbasierten KI-Assistenten entwickelt, der Wissen aus der Schweiß-FMEA (Fehlermöglichkeits- und Einflussanalyse) mithilfe des fallbasierten Schließens (Case-Based Reasoning) wiederverwendbar macht. Eine Streamlit-basierte Retrieval-Augmented-Generation-(RAG)-Anwendung unter Einsatz von LLMs.
LLM-Driven MBSE Requirements Automation
Entwicklung einer webbasierten Anwendung für interaktives Modellbasiertes Systems Engineering (MBSE) zur Anforderungsdiagramm-Erstellung. Dabei wurde die Perplexity AI API, Python und Streamlit genutzt, um eine intuitive und benutzerfreundliche Oberfläche für die Modellierung und Visualisierung von Anforderungen bereitzustellen.


Feature Importance in Time Series Data
Interaktive Python- und Streamlit-Webanwendung zur Analyse und Visualisierung der Merkmalswichtigkeit in Zeitreihen des Energieverbrauchs von CNC-Maschinen, die den Vergleich mehrerer Erklärmethoden zur Identifikation entscheidender Einflussfaktoren ermöglicht.
Google Cloud-Enabled Analytics and Forecasting for MPD
Entwicklung einer umfassenden Analyselösung zur Prognose von Umsatz und Gewinn mobiler Produkte mit SAP Datasphere, Google Cloud, BigQuery ML, Vertex AI und Looker Studio, die datengetriebene Einblicke und strategische Entscheidungsunterstützung für Fertigung und Produktvertrieb ermöglicht.


Visualization of Process Engineering (Calciner) using unity 3d
Mitarbeit an einem interdisziplinären Projekt mit Verfahrenstechnikstudierenden zur Entwicklung einer 3D-Kalzinierungsprozess-Simulation, unter Verwendung von SolidWorks 2023, Blender und Unity 3D für präzises Modellieren und interaktive Visualisierung.
Sales - Profit Visualization using power BI
Erstellung eines interaktiven Power BI-Dashboards zur Analyse von Verkaufs- und Gewinntrends eines US-Supermarkts auf Basis eines mehrjährigen Kaggle-Datensatzes. Ermöglicht die dynamische Erkundung regionaler, segmentbezogener und produktkategoriespezifischer Leistungen durch verschiedene Visualisierungen.

🛠️ Bachelorprojekte und Aktivitäten
PARSEC Racing – Student Formula Kart Projekt (2018–2019)
Mitbegründung von PARSEC Racing (einem studentischen Motorsportteam) am Dayananda Sagar College of Engineering (Bengaluru, Indien) sowie Leitung eines 20-köpfigen Studierendenteams zur Konzeption und zum Aufbau eines von einem Verbrennungsmotor angetriebenen Go-Karts von Grund auf, zur Einwerbung von Industrie-Sponsoring und zur Teilnahme an mehreren studentischen Karting-Meisterschaften bundesweit.


Portable e-Cycle - Bachelorarbeitsprojekt (2019 - 2020)
Leitung eines vierköpfigen Teams am Dayananda Sagar College of Engineering (Bengaluru, Indien) als Projektleiter und CAD-Designer mit dem Ziel, ein faltbares, portables E-Bike mit integrierten mechanischen und elektrischen Antriebssträngen zu realisieren; Umsetzung des vollständigen End-to-End-Produktentwicklungszyklus – von Konzeptvisualisierung und Anforderungsdefinition über detailliertes CAD-Design und FEA-basierte Validierung bis hin zu Fertigung und finaler Montage gemeinsam mit dem Team.
FMEA KNOWLEDGE REUSE (Masterarbeit)
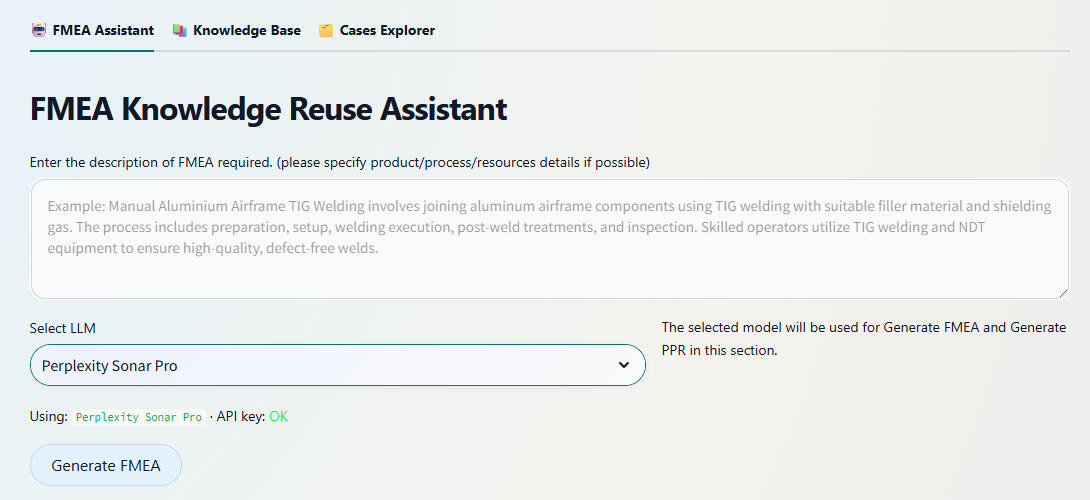
Gut zu lesen, wenn Sie neu in FMEA und Reliability Engineering sindZuverlässigkeitstechnik (Reliability Engineering) ist die Disziplin, die darauf abzielt, die Fähigkeit von Systemen, Komponenten oder Prozessen vorherzusagen, zu analysieren und zu verbessern, geforderte Funktionen unter definierten Bedingungen über festgelegte Zeiträume ohne Ausfall zu erfüllen. Sie nutzt probabilistische Modellierung, statistische Analysen, beschleunigte Lebensdauertests und Ausfalldatenanalytik, um Zuverlässigkeitskennzahlen (z. B. Mean Time Between Failures (MTBF), Ausfallraten λ) zu quantifizieren, Redundanz/Robustheit auszulegen und Instandhaltungsstrategien zu etablieren, die Stillstandszeiten und Lebenszykluskosten minimieren und zugleich die operative Verfügbarkeit maximieren.Fehlermöglichkeits- und Einflussanalyse (FMEA) ist eine systematische, strukturierte Methode im Engineering zur Identifikation potenzieller Fehlermodi innerhalb eines Systems, Designs oder Prozesses, zur Bewertung ihrer Ursachen und Auswirkungen sowie zur Priorisierung von Gegenmaßnahmen anhand von Schweregrad, Auftretenswahrscheinlichkeit und Entdeckbarkeit. Mittels tabellarischer Analyse dokumentiert die FMEA mögliche Ausfallmechanismen je Komponente, deren Auswirkungen auf verschiedenen Systemebenen (lokal, Teilsystem, gesamtes System) sowie Präventions- und Entdeckungsmaßnahmen, sodass Entwicklungsteams risikoreiche Fehlermodi proaktiv vor der Produktion adressieren können. Diese Risikopriorisierung – typischerweise über die Risiko-Prioritätszahl (RPN = Severity × Occurrence × Detection) – steuert die Ressourcenzuteilung zur Beseitigung sicherheitskritischer Themen und zur Erhöhung der Gesamtzuverlässigkeit des Systems.Kurze ZusammenfassungIm Rahmen meiner Masterarbeit an der OvGU habe ich einen webbasierten FMEA-Assistenten entwickelt, der darauf ausgerichtet ist, bestehendes Wissen aus Schweiß-Fehlermöglichkeits- und Einflussanalysen (FMEA) wiederzuverwenden, statt Risikoanalysen jedes Mal von Grund auf neu zu erstellen. Die Anwendung kombiniert Case-Based Reasoning (CBR), das CRISP‑DM-Datenmining-Prozessmodell sowie Retrieval‑Augmented Generation (RAG) mit LLMs, um Ingenieurinnen und Ingenieuren sowie fachlichen und nicht-fachlichen Nutzergruppen das Suchen, Anpassen und Erweitern historischer FMEAs zu ermöglichen. Das System ist mit Python und Streamlit implementiert und nutzt ein Supabase-Backend (PostgreSQL + pgvector) für die semantische Suche über gespeicherte FMEA-Fälle.Problemstellung1. Wie können unterschiedliche Ingenieurinnen/Ingenieure bzw. Nutzer vorhandene Schweiß-FMEA-Daten, die derzeit in proprietären Formaten (z. B. APIS-IQ-Exporte) vorliegen, effizient wiederverwenden, anstatt für jede neue Produkt- oder Prozessvariante ähnliche Analysen manuell neu zu erstellen?2. Können LLMs in Kombination mit einer Fallbasis und robuster Retrieval-Logik qualitativ hochwertige FMEA-Zeilen und Process Element Requirements (PER) erzeugen, ohne sicherheitskritische oder irrelevante Fehlermodi zu halluzinieren?3. Wie lässt sich ein Human-in-the-Loop-Workflow so gestalten, dass Expertinnen und Experten die Kontrolle behalten – Inhalte bearbeiten, freigeben und erweitern – und gleichzeitig Produktivitäts- und Konsistenzvorteile realisieren?MethodikDie App ist als dreiseitige Streamlit-Oberfläche konzipiert und basiert auf einer CBR- und RAG-Architektur:FMEA Assistant Page: Ingenieurinnen/Ingenieure bzw. Nutzer beschreiben einen Schweißschritt oder ein Prozesselement in natürlicher Sprache.Das Backend ruft semantisch ähnliche frühere Fälle aus der Supabase-Fallbasis mittels pgvector-Embeddings ab und übergibt sie anschließend an ein LLM.Das LLM erzeugt Entwürfe für FMEA-Zeilen (Fehlermodi, Ursachen, Auswirkungen und Maßnahmen) sowie optional PER-Einträge mit Input- und Output-Produkten, Prozessen und Ressourcen, die für die spezifizierte Operation erforderlich sind.Nutzer prüfen und bearbeiten alle vorgeschlagenen Zeilen in einer interaktiven Tabelle, bevor sie diese als neuen Fall speichern.Knowledge Base Page: Nutzer laden bestehende APIS-IQ-Excel-Exporte hoch, die als Rohdateien in einem Supabase-Storage-Bucket gespeichert und automatisch in strukturierte Tabellen geparst werden.Die geparsten Daten werden in das FMEA-Schema (Fälle, FMEA-Zeilen, Input- und Output-Produkte, Prozesse und Ressourcen) geschrieben und für die semantische Suche in Text-Embeddings umgewandelt.Aus derselben Ansicht können Nutzer neue PERs mithilfe des LLM auf Basis der importierten Tabellen generieren oder PERs manuell eingeben und als neue Fallbasis speichern.Cases Explorer Page: Bietet eine durchsuchbare Übersicht über alle gespeicherten Fälle und FMEA-Zeilen.Ingenieurinnen/Ingenieure bzw. Nutzer können vorhandene Einträge inspizieren, filtern und daraus lernen. Diese Ansicht unterstützt die Pflege der Fallbasis und schließt den CBR-Kreis, indem überarbeitete, fachlich validierte Erkenntnisse erfasst werden.Der gesamte Workflow wird durch einen Human-in-the-Loop-CRISP‑DM-Prozess geführt: Business Understanding (Wiederverwendung von Schweiß-FMEAs), Data Understanding und Preparation (Parsing von APIS IQ, Normalisierung von FMEA-Zeilen, Berechnung von Embeddings), Modeling (CBR + RAG-Pipeline), Evaluation (Expertenreview der Vorschläge) und Deployment (Streamlit-App im täglichen Engineering-Einsatz).Wichtigste Erkenntnisse1. Der Assistent macht historische FMEAs zu einer lebendigen Fallbasis, sodass Ingenieurinnen und Ingenieure ähnliche Schweißszenarien suchen und anpassen können, anstatt Risikoanalysen von Grund auf neu zu erstellen.2. Retrieval‑Augmented Generation verbessert die Qualität der LLM-Ausgaben deutlich: Vorschläge werden in realen Unternehmensdaten verankert, während die UI sicherstellt, dass Menschen die finalen Entscheider bleiben.3. Ein schlanker Tech-Stack (Streamlit + Supabase + pgvector + externe LLM-API) reicht aus, um ein forschungsnahes, produktionsorientiertes CBR/RAG-System für sicherheitskritisches Engineering-Wissen umzusetzen.Schritte zur Nutzung der App1. Zugriff auf die Anwendung: Aufrufen: https://fmea-cbr.streamlit.app/2. Wählen Sie je nach Aufgabe eine Seite aus:FMEA Assistant:
- Geben Sie eine kurze Beschreibung des Schweißprozesses oder der PER ein.-Hinweis: Da die Wissensbasis überwiegend in englischer Sprache aufgebaut ist, sollten Eingaben/Prompts ebenfalls auf Englisch formuliert werden, um optimale Ergebnisse bei Suche und Generierung zu erzielen.Beispiel-Prompt: Create process level FMEA rows for an Automated resistance spot welding process on automotive body parts. Focus on a maximum of 5 critical failure modes, including causes, effects, and recommended actions.- Lassen Sie die App ähnliche historische Fälle abrufen und vorgeschlagene FMEA-Zeilen generieren.
- Bearbeiten Sie alle Felder nach Bedarf und speichern Sie die freigegebenen Zeilen als neuen oder aktualisierten Fall.Knowledge Base:
- Laden Sie einen APIS-IQ-Excel-Export hoch.
- Prüfen Sie die geparste FMEA-Tabelle in der Vorschau und bestätigen Sie den Import.
- Optional: Generieren Sie neue PERs mithilfe des LLM oder erfassen Sie diese manuell und speichern Sie sie.Cases Explorer:
- Durchsuchen Sie bestehende Fälle und FMEA-Zeilen mit Filtern.
- Öffnen Sie einen Fall, um dessen Inhalte zu prüfen und daraus zu lernen.3. Verwenden Sie die gespeicherten Fälle als Kontext für zukünftige Analysen und bauen Sie schrittweise eine reichhaltigere, semantisch durchsuchbare Wissensbasis für Schweiß-FMEAs auf.
LLM-Driven MBSE Requirements Automation

KurzfassungIm Rahmen meines Masterprogramms wurde in Zusammenarbeit mit der Systems Engineering Abteilung der OvGU eine Webanwendung entwickelt, die speziell für die Erstellung SysML-kompatibler MBSE-Anforderungsdiagramme konzipiert ist. Die App erzeugt Dateien, die vollständig mit der MBSE-Designsoftware Gaphor kompatibel sind, und wurde mit Python, Streamlit sowie der Perplexity AI API umgesetzt.Problemstellung1. Wie können Systems Engineers oder Nicht-Experten präzise MBSE/SysML Anforderungsdiagramme einfach erstellen, ohne tiefgehende Kenntnisse spezialisierter Designwerkzeuge zu besitzen?2. Kann KI die Übersetzung von einfachen, englischen Anforderungen in industriekonforme MBSE-Modelle beschleunigen?3. Wie ermöglichen wir Nutzern eine effiziente Modifikation und Pflege von Anforderungsmodellen, die sowohl manuelle als auch automatisierte Arbeitsabläufe unterstützt?MethodikEntwicklung und Implementierung einer Streamlit-Webanwendung mit drei Modi:Manueller Modus: Nutzer geben bis zu 20 Anforderungen (mit Überschrift und Beschreibung) ein. Die App generiert sofort eine Gaphor SysML-Anforderungsdatei, die heruntergeladen werden kann – ideal für Nutzer, die mit Anforderungen vertraut, aber keine MBSE-Zeichenwerkzeuge gewohnt sind.KI-basierter Modus: Nutzer geben Anforderungen in einfachem Englisch ein. Das integrierte LLM interpretiert und wandelt diese Eingaben in korrekt strukturierte, industriekonforme SysML-Anforderungsdiagramme um und behandelt die Komplexität im Hintergrund.Modifikationsmodus Nutzer laden eine bestehende Gaphor-Datei hoch und führen CRUD-Operationen – Bearbeiten, Löschen oder Hinzufügen von Anforderungen – direkt über die Oberfläche durch, was Pflege und Iteration vereinfacht.Jede Datei ist zu 100% mit Gaphor kompatibel, was Reibungsverluste im MBSE-Workflow vermeidet. Robuste Backend-Logik für Diagrammstrukturierung, KI-Aufforderungen und Dateiexport wurde gemäß SysML-Standards implementiert.Wesentliche Erkenntnisse1. Das Tool senkt die Barriere für die Erstellung hochwertiger MBSE-Diagramme erheblich und macht Requirements Engineering für alle zugänglich.2. KI-Unterstützung beschleunigt den Spezifikationsprozess und minimiert Fehler in Anforderungsmodellen.3. Die direkte Gaphor-Kompatibilität optimiert nachgelagerte Systemdesign- und Dokumentationsprozesse.Schritte zur Nutzung der App1. App aufrufen: Besuchen Sie: https://llmautomation.streamlit.app/2. Wählen Sie Ihren gewünschten Modus:
Manueller Modus: Geben Sie bis zu 20 Anforderungen ein; laden Sie die Gaphor-kompatible Datei herunter.KI-basierter Modus: Schreiben Sie Anforderungen in einfachem Englisch; lassen Sie die App und das LLM ein rigoroses SysML MBSE-Diagramm erstellen.Modifikationsmodus: Laden Sie eine bestehende Anforderungsdatei hoch; fügen Sie nach Bedarf Anforderungen hinzu, bearbeiten oder löschen Sie diese.3. Laden Sie Ihre Gaphor-Datei herunter.4. Öffnen Sie die Datei mit der Gaphor MBSE-Designsoftware, um Ihr SysML-Anforderungsdiagramm anzusehen und weiter zu bearbeiten.Falls Sie das Gaphor-Tool noch nicht installiert haben, können Sie die neueste Version für Windows oder Mac von der offiziellen Webseite herunterladen:
Gaphor herunterladen (Windows & Mac)Beispiel KI-Aufforderung: Create concept level requirements for building a coffee machine, keep a maximum of 5 important requirements.Eine Beispielausgabe der Gaphor-Software ist unten zu sehen.

Feature Importance in Time Series Data

KurzfassungDieses akademische Projekt resultierte in einer interaktiven Webanwendung zum Vergleich von Methoden der Merkmalswichtungsanalyse in Zeitreihen des Energieverbrauchs von CNC-Maschinen. Die App wurde mit Python und Streamlit entwickelt und zeigt vorab berechnete Ergebnisse unserer Experimente, wodurch Nutzer die wichtigsten Treiber des Energieverbrauchs verschiedener Maschinen, Materialien und Datensätze visuell erkunden und vergleichen können. Die App ist öffentlich zugänglich unter featureimportance app.Problemstellung / Forschungsfragen1. Wie können wir transparent die kritischsten Faktoren identifizieren und vergleichen, die den Energieverbrauch industrieller CNC-Maschinen anhand realer Prozessdaten beeinflussen?2. Welche Methoden der Merkmalswichtigkeitsanalyse liefern die robustesten und aussagekräftigsten Erklärungen für Zeitreihen, die unterschiedliche Maschinen, Materialien und Produktionsbedingungen abbilden?3. Können wir ein intuitives Webwerkzeug erstellen, das Ingenieuren ermöglicht, Ergebnisse aus verschiedenen Erklärmethoden interaktiv zu untersuchen und zu interpretieren?Schritte und Methodik1. Datenvorbereitung und -vorverarbeitungDatenherkunft: Der Datensatz umfasst Aufzeichnungen von zwei Maschinen (CMX, DMC), zwei Materialien (Aluminium und Stahl) und zwei Bauteilen (CP1, CP2) mit ursprünglich 92 Spalten.Vorverarbeitung:
- Entfernung von 28 Spalten mit fehlenden (NaN) Werten.
- Weitere 6 Spalten wurden aufgrund geringer Relevanz oder Redundanz eliminiert.
- 52 signifikante Merkmale und 4 energierelevante Zielspalten blieben für die Analyse erhalten.Experimentelle Arbeit:
- Alle Datenbereinigungen, Merkmalsentwicklungen und experimentellen Läufe wurden offline im Rahmen der Forschungsphase durchgeführt.
- Die Ergebnisse der Experimente (Diagramme, Tabellen und Ranglisten) wurden anschließend in die statische Webanwendung integriert, um eine interaktive Ansicht zu ermöglichen.2. Implementierte Methoden zur MerkmalswichtigkeitsanalysePermutation Importance: Bewertet Genauigkeitsverluste bei zufälliger Vertauschung von Merkmalwerten und hebt einflussreiche Prädiktoren bei Ensemblemodellen hervor.Integrated Gradients: Verwendet gradientenbasierte Attribution, um die Merkmalsrelevanz in neuronalen Modellen (LSTM, FNN) zu quantifizieren.WINit: Für Zeitreihen entwickeltes Verfahren, das zeitabhängige Effekte und verzögerte Einflüsse auf den Energieverbrauch erfasst.LIME: Erzeugt interpretierbare, lokale Surrogatmodelle zur modellagnostischen Erklärung von Vorhersagen.3. AnwendungsarchitekturStatischer Ergebnisbrowser:
- Nutzer erkunden vorab geladene Ergebnisse aus umfassenden Experimenten zum vollständigen Datensatz.
- Alle Vergleichsdiagramme, Tabellen und Metriken basieren auf diesen kontrollierten experimentellen Läufen; es ist kein Daten-Upload oder Benutzerdaten erforderlich.—no data upload or user-supplied data is required.
- Ergebnisse sind zum Vergleich nach Maschinentypen, Materialien (Aluminium/Stahl) und unterschiedlichen Methoden zur Merkmalswichtigkeitsanalyse organisiert.Nutzererlebnis:
- Auswahl unterschiedlicher Techniken und Szenarien über die App-Oberfläche.
- Sofortiger Vergleich von Erklärungen und gerankten Merkmalswichtungen über Experimente und Datensätze hinweg.Wesentliche Erkenntnisse1. Die Merkmalswichtigkeit variiert signifikant je nach Maschine, Material und gewählter Erklärmethode, was die Notwendigkeit multifacettierter Analysen in industriellen Anwendungen unterstreicht.2. Die Bereitstellung einer benutzerfreundlichen Oberfläche für vorgegebene experimentelle Ergebnisse macht Erkenntnisse auch für Ingenieure und Stakeholder ohne technische Vorkenntnisse zugänglich.3. Spezialisierte Methoden zur Erklärung von Zeitreihen (wie WINit und Integrated Gradients) offenbaren differenzierte, zeitliche Muster im Energieverbrauch, die klassische Methoden möglicherweise übersehen.Schritte zur Nutzung der App1. App aufrufen: Besuchen Sie https://featureimportance.streamlit.app/.2. Experimente durchsuchen: Wählen Sie Merkmalswichtigkeitsmethoden und Szenarien mithilfe der Steuerung der App; kein Daten-Upload erforderlich.3. Ergebnisse ansehen: Erkunden Sie sofort visuelle Vergleiche, Merkmalsrankings und Metriken basierend auf Experimenten mit verschiedenen Maschinentypen, Materialien und Bauteilen.4. Erkenntnisse interpretieren: Nutzen Sie Tabellen und Diagramme, um zu verstehen, welche Faktoren den Energieverbrauch unter verschiedenen Betriebsbedingungen am stärksten beeinflussen.Der zugrunde liegende Datensatz und alle dargestellten Ergebnisse basieren auf Offline-Experimenten, die eine konsistente und robuste Vergleichsumgebung gewährleisten.Die derzeitige Anwendung demonstriert die Analyse der Merkmalswichtigkeit unter Verwendung vorab berechneter Ergebnisse des zugrundeliegenden Datensatzes. Dieses Framework kann jedoch leicht für den realen Industrieeinsatz angepasst werden. Für eine breitere oder kommerzielle Nutzung könnte eine CI/CD-Pipeline eingerichtet werden, die es Nutzern ermöglicht, eigene Datensätze direkt in die App hochzuladen. Das System würde dann automatisch Datenvorverarbeitung, Modellevaluation und Merkmalswichtigkeitsanalyse durchführen und interaktive, aktuelle Visualisierungen über die Streamlit-Oberfläche bereitstellen. Durch diese Erweiterung würde die App von einem statischen Ergebnisbrowser zu einer dynamischen, skalierbaren Plattform für kontinuierliche industrielle Analysen und Erkenntnisgewinnung werden.
Google Cloud-Enabled Analytics and Forecasting for MPD
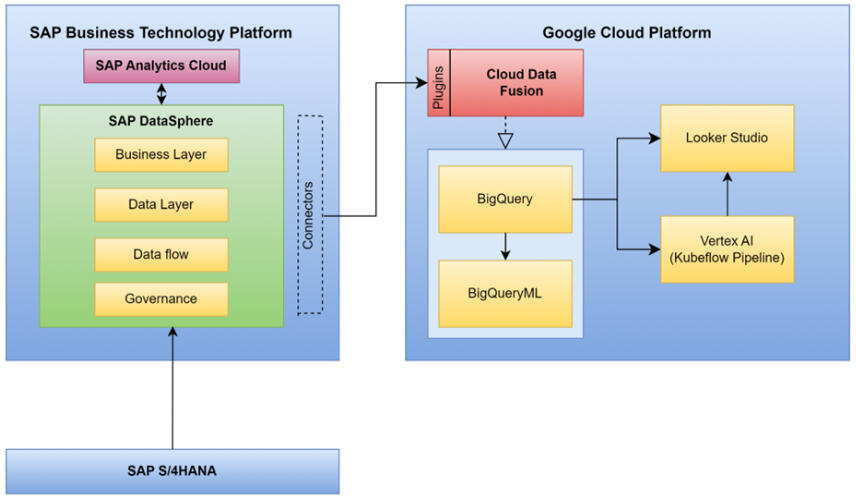
KurzfassungIn diesem Projekt wurden Verkaufs- und Gewinnanalysen sowie Prognosen für mobile Produkte eines globalen Unternehmens durchgeführt, basierend auf einem umfangreichen Datensatz aus internen SAP Datasphere-Systemen. Der vollständige Data-Science- und Analysezyklus – von der Marktsegmentierung und Produktauswahl über maschinelles Lernen für Prognosen bis hin zu interaktiven Dashboards – wurde mit der Google Cloud Platform (BigQuery, BigQuery ML, Kubeflow, Vertex AI und Looker Studio) implementiert und unterstützt strategische Entscheidungen in Fertigung und Produktvertrieb. Die Präsentation ist öffentlich zugänglich unter GCP Market Prediction & Analysis.Problemstellung1. Wie kann ein globales Mobilitätsunternehmen die Produktion und den Verkauf strategisch planen, indem es historische Trends tiefgreifend analysiert und zukünftige Verkäufe, Materialbedarf und Gewinne prognostiziert?2. Wie können Kundenmärkte mithilfe von maschinellem Lernen optimal segmentiert werden, um zielgerichtete Planungen zu ermöglichen?3. Welche Produktkategorien sind am profitabelsten und nachhaltigsten für das zukünftige Unternehmenswachstum?4. Wie sollte das Unternehmen Erkenntnisse visuell kommunizieren, um datenbasierte Entscheidungen im sich wandelnden Markt zu fördern?Methodik und Schritte1. Datenakquise und -vorbereitungDatenextraktion:
- Historische Daten zu Kunden, Bestellungen, Materialien, Produkten und Gewinnen wurden aus dem SAP Datasphere des Unternehmens mithilfe von Cloud Data Fusion für eine nahtlose, visuelle Datenpipeline gewonnen.
- Integration externer Wechselkursdaten zur Harmonisierung von Preisen in lokaler Währung (EUR) und USD.Datenumwandlung & -bereinigung:
- Upload und Transformation von CSV-Daten in Google Cloud Storage und BigQuery.
- Zuordnung von Schemata, Standardisierung von Städtenamen und Produktbezeichnungen, Umgang mit fehlenden oder inkonsistenten Datentypen und Anpassung von Spaltentrennzeichen für korrekte Datenaufnahme.2. Marktsegmentierung und Clustering- Kundensegmente wurden mittels K-Means-Clustering (BigQuery ML) geordnet und nach geografischen Standorten (Ländern) gruppiert.
- Diese Methode lieferte strategische Einblicke in regionale Kundenpräferenzen, lokale Vorschriften und Lieferkettenlogistik.
- Cluster und Kundendistributionen wurden auf interaktiven Karten und Diagrammen (Looker Studio) visualisiert, um die Marktsegmentierung klar zu kommunizieren.3. Produktauswahl- Analyse aller Produktkategorien zur Ermittlung von Umsatz und Gewinn im Zeitraum 2011–2023.
- Touring- und Offroad-Bikes wurden als die lukrativsten Produktkategorien identifiziert, die hohe Umsätze mit gesunden Gewinnmargen verbinden und nachhaltiges Geschäft gewährleisten.4. Analyse der bisherigen Leistung- Konsolidierung der wichtigsten Datentabellen (Bestellungen, Produkte, Materialien, Kunden) in BigQuery.
- Erstellung zusammengefasster Tabellen mit monatlichen, länderspezifischen Übersichten zu Verkaufszahlen, Umsätzen, Materialkosten und Gewinnen zur granularen historischen Bewertung ausgewählter Produkte.5. Prognose von Verkäufen, Materialbedarf und Gewinnen mittels maschinellem Lernen- Entwicklung und Einsatz von Zeitreihenmodellen (Exponentielle Glättung) in Python-Notebooks, integriert mit BigQuery-Daten über BigQuery ML.
- Modellierung und Prognose von 24 Monaten (2025–2026) Verkaufszahlen, Umsätzen, Ausgaben und Gewinnen für jedes Land und Produkt.
- Erstellung von Prognosen für zukünftigen Materialbedarf basierend auf vorhergesagten Verkaufszahlen und Stücklistenanalysen.
- Orchestrierung und Automatisierung dieser Prozesse mit Kubeflow-Pipelines und Vertex AI zur Sicherstellung von Reproduzierbarkeit und Skalierbarkeit.6. Visualisierung und Reporting- Alle Ergebnisse – Marktcluster, historische Trends, Prognosen und wesentliche Gewinnfaktoren – wurden in Looker Studio Dashboards visualisiert.
- Dashboards ermöglichten den Vergleich von vergangenen und zukünftigen Verkaufszahlen, Materialbedarf und Rentabilität über verschiedene Märkte und Produkte hinweg.
- Handlungsempfehlungen für Produktionsplanung, Beschaffung und Marketingstrategie basierend auf den visualisierten Erkenntnissen wurden berichtet.Wesentliche Erkenntnisse1. Die Kombination aus cloudbasierter Datenintegration, leistungsfähiger ML/AI-Modellierung und interaktiven Dashboards ermöglicht eine durchgängige Analyselösung für die Fertigung in großem Maßstab.2. Die regionale Marktsegmentierung verbesserte die Zielgenauigkeit für Verkaufs- und Produktionsplanung.3. Die fokussierte Analyse margenstarker Produktkategorien unterstützt die Ressourcenallokation für maximalen Geschäftseinfluss.4. Prognosen zeigten rückläufige Verkaufszahlen bei Hauptprodukten, verbesserten jedoch die Gewinnmargen, was auf erfolgreiche Kosten- und Preisstrategien hinweist; zukünftige Trends machen jedoch eine Neubewertung der Wachstums-, Beschaffungs- und Lieferkettenpolitik erforderlich.5. Die Pipeline- und Plattformarchitektur ist robust und erweiterbar für zukünftige strategische Entscheidungen in dynamischen Fertigungsumgebungen.Schritte zur Erweiterung der Analyse1. Datenintegration:
Neue Geschäfts-, Betriebs- oder externe Marktdaten in SAP und Google Cloud Storage einpflegen und hochladen.2. Marktsegmentierung:
Clustering-Modelle mit aktuellen Daten aktualisieren, um eine verfeinerte Kundensegmentierung zu ermöglichen.3. Produktauswahl:
Analysen an neue Produktlinien oder sich ändernde Geschäftsprioritäten anpassen.4. Prognosemodelle ausführen:
Automatisierte ML-Pipelines (Kubeflow/Vertex AI) für Verkaufs-, Gewinn- und Materialprognosen mit den neuesten historischen Daten ausführen.5. Visualisierung und Reporting:
Erkenntnisse über Looker Studio Dashboards präsentieren und an Stakeholder weitergeben für transparente, datenbasierte Planung.Dieses Projekt bietet eine skalierbare Blaupause für fortgeschrittene Analytik in der Fertigung – mit robuster Datenverarbeitung, automatisiertem ML und umsetzbarer Visualisierung für moderne, mehrmarktige Geschäftsanforderungen.PräsentationFür detaillierte Folien zur vollständigen Analyse und Implementierung besuchen Sie bitte die Präsentation hier. Diese ist leider nur in englischer Sprache verfügbar: Market Prediction & Analytics
Visualization of Process Engineering (Calciner) using unity 3d

KurzfassungDieses interdisziplinäre Projekt führte zur umfassenden 3D-Simulation und Visualisierung eines internen Drehkalziners – einem wichtigen industriellen Gerät zur Materialverarbeitung – und vereinte Ingenieurbau, Prozesssimulation und interaktive Softwareentwicklung. Ich war verantwortlich für die 3D-Komponentenmodellierung und die Entwicklung der Unity 3D Anwendung und arbeitete eng mit Studierenden der Verfahrenstechnik an der OvGU zusammen, die mit ihrem Prozessfachwissen die realitätsgetreue Simulation industrieller Bedingungen gewährleisteten. Die App ist sowohl als native Windows-Anwendung als auch als WebGL-Demo verfügbar: Web App LinkProblemstellung1. Wie lassen sich komplexe verfahrenstechnische Prozesse – wie die industrielle Kalzinierung – visuell intuitiv und zugänglich für Studierende und Auszubildende darstellen?2. Kann ein virtuelles 3D-Abbild mit interaktiven Animationen und Prozessbeschreibungen die Lücke zwischen theoretischem Wissen und praktischer Gerätesteuerung schließen?3. Wie arbeiten multidisziplinäre Teams effizient zusammen, um lehrreiche Anwendungen zu erstellen, die Gerätemechanik, Steuerung und Prozessablauf realitätsgetreu abbilden?Methodik und EntwicklungsschritteDas Projektteam setzte sich aus Studierenden des Digital Engineering (Software, 3D-Modellierung, Animation) und der Verfahrenstechnik (Prozesssimulation, Fachwissen) der OvGU zusammen.Die Arbeit erfolgte in enger Zusammenarbeit mit Fakultätsbetreuern beider Fachbereiche, um Authentizität sowohl in Ingenieursinhalt als auch digitaler Umsetzung sicherzustellen.1. Sprintbasierte agile EntwicklungAgiler Prozess: Das komplette Projekt wurde mit einer agilen Methodik über 10 Sprints in 5 Monaten geführt, unter Beachtung akademischer Best Practices für Produktivität und Klarheit.Sprintplanung: Vor jedem Sprint definierte das Team konkrete Ziele (z.B. Modellierung des Drehzylinders, Hinzufügen von Bedienfeldern, Skripting von Animationen, Integration der UI-Navigation).Regelmäßige Reviews: Alle zwei Wochen fand ein Meeting mit Fortschrittspräsentationen, Demos, Code-Sharing und Feedback statt, um technische Ausrichtung und Bildungsnutzen zu gewährleisten.Adaptiver Workflow: Sprint-Retrospektiven ermöglichten es dem Team, Entwürfe schnell anzupassen, Fehler zu beheben und Funktionen auf Basis von Feedback der Betreuer und Kollegen zu verbessern.Dokumentation: Jeder Sprint schloss mit aktualisierter Dokumentation und Planung der nächsten Phase ab.Dieser Prozess sicherte nicht nur die termingerechte Lieferung gemäß Anforderungen, sondern demonstrierte auch die Fähigkeit, effektiv in modernen iterativen Projekten zu arbeiten.2. Detaillierte KomponentenmodellierungDatenerfassung: Messung und Aufzeichnung physikalischer Parameter und Betriebsdetails des universitären Pilotanlagen-Drehkalziners.SolidWorks 2023: Erstellung hochpräziser Modelle wesentlicher Apparatebauteile: Drehzylinder, Motor, Lagerrollen, Heizwendel, Bedienfeld und Abgassystem.Blender: Verfeinerung und Texturierung dieser Modelle für realistische Simulationselemente. Export der Modelle im .fbx-Format für Unity-Integration.3. Unity 3D Application Development- Import aller Assets und Aufbau interaktiver 3D-Szenen mit Unity 3D.
- Entwicklung von C#-Skripten zur Simulation von Prozessabläufen: Drehung des Zylinders, Materialfluss, Temperaturänderung (mit Farbfeedback) und Animation von Bauteilen.- Erstellung eines mehrszenarigen Workflows:
Intro- und Erläuterungsszenen für Theorie und Prozesskontext.
Bauteilzerlegungsszenen mit 3D-Interaktivität zur Beschreibung einzelner Komponenten.
3D-Erkundungsansicht mit Zoom, Drehung und Hervorhebung von Komponenten.
Simulationsmodus zur Animation des Kalzinierungsprozesses mit variierenden Prozessparametern.4. UX, Workflow und Erweiterungen- Integration informativer Dialoge, Tooltips, Navigation und Credits für Übersichtlichkeit und Nutzerbindung.
- Verwendung robuster Softwaremuster (Singleton, ECS, Decorator) für Struktur und Wartbarkeit der Anwendung.
- Iterative/agile Entwicklung mit regelmäßigem Feedback von Informatik- und Verfahrenstechnikbetreuern.5. Bereitstellung- Erstellung und Test einer hochauflösenden Windows-Desktopanwendung (Optimiert für 1920x1080).
- Portierung zu WebGL für universellen browserbasierten Zugriff und Teilen.Wesentliche ErkenntnisseVerbindung der Disziplinen: Effektive Zusammenarbeit zwischen Softwareingenieuren und Verfahrenstechnik-Experten ist entscheidend für authentische, lehrreiche digitale Abbilder in der Ingenieurwissenschaft.Verbessertes Lernen: 3D-Simulation mit interaktiver Erkundung und Animation bietet einen erheblichen Vorteil beim Verständnis von Struktur, Betrieb und theoretischen Grundlagen industrieller Anlagen.Vielseitige Plattform: Die Anwendung dient sowohl als Lernhilfe als auch als Demonstrationswerkzeug für Studierende, Lehrende und Forschende.Schritte zur Nutzung der App1. Zugriff auf die WebGL-Version: Diese Webanwendung ist leider nur in englischer Sprache verfügbar. Web App Link.2. Navigation der Benutzeroberfläche:
- Starten Sie vom Hauptbildschirm: Einführung, Credits ansehen oder Simulation starten.3. Erkunden der Erklärszenen:
- Lesen Sie über den Kalzinierungsprozess und den industriellen Kontext.
- Durchlaufen Sie detaillierte, animierte Zerlegungen der einzelnen Komponenten.4. Nutzung der 3D-Ansicht:
- Drehen, zoomen und inspizieren Sie den digitalen Zwilling des Drehkalziners mit benutzerfreundlichen Steuerungen.5. Starten der Prozesssimulation:
- Starten Sie die Simulation, um Kalzinierung, Material- und Wärmeströmung sowie temperaturabhängige Farbänderungen zu visualisieren.6. Beenden oder Wiederholen
- Beenden Sie die Simulation, wiederholen Sie Szenen oder kehren Sie je nach Bedarf zurück zum Startbildschirm.Zukünftige Erweiterungen-Integration von Echtzeitprozessparameter-Steuerungen (z.B. Temperatur, Zufuhrrate) für experimentelle Erkundungen.
- Einbindung von Quizzen und interaktiven Herausforderungen zur vertieften Nutzerbindung.
- Mögliche Erweiterung zu Mehrszenario-Simulationen und VR-basiertem, immersivem Lernen.Dieses Projekt ist ein Modellbeispiel, wie agile Methoden, Software-Engineering-Disziplin und starke interdisziplinäre Zusammenarbeit wirkungsvolle Lehrmittel für die Verfahrenstechnik und darüber hinaus schaffen können.
Sales - Profit Visualization using power BI
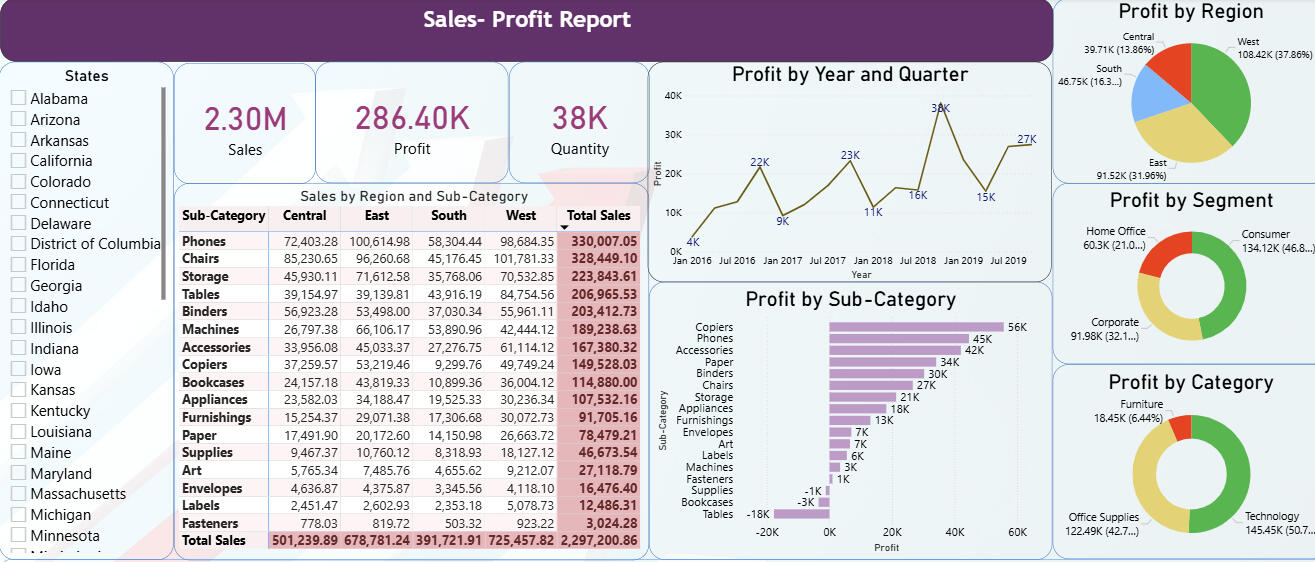
KurzfassungDieses Projekt präsentiert ein interaktives Power BI-Dashboard, das mithilfe eines umfassenden, mehrjährigen Verkaufs- und Gewinn-Datensatzes für einen US-Supermarkt, ursprünglich von Kaggle bezogen, entwickelt wurde. Das Dashboard bietet aussagekräftige Visualisierungen zur Analyse regionaler Profitabilität, Kundensegmente, Produktkategorien und Verkaufstrends über die Zeit. Das Projekt hebt fortgeschrittene Datenvisualisierungstechniken hervor und ermöglicht eine tiefgehende Erkundung von Leistungskennzahlen durch eine benutzerfreundliche Oberfläche.Problemstellung1. Wie können Einzelhandelsdaten effektiv visualisiert werden, um wichtige Erkenntnisse über Verkaufs- und Gewinnmuster in verschiedenen Kundensegmenten, Produktkategorien und geografischen Regionen zu gewinnen?2. Wie entwickeln sich die Rentabilitätstrends im Zeitverlauf, und wie unterscheiden sie sich zwischen verschiedenen Unterkategorien und Marktregionen?3. Welche Kundensegmente tragen am meisten zur Gesamtprofitabilität bei, und welche Produktkategorien weisen ein stetiges Umsatzwachstum auf?4. Wie können Nutzer komplexe multidimensionale Verkaufsdaten interaktiv erkunden, um Geschäftsentscheidungen und strategische Planung zu unterstützen?Datensatzübersicht- Der Datensatz umfasst ca. 9.994 Einträge mit Verkaufsdaten von 2016 bis 2019.
- Die Maßeinheiten sind US-Dollar (USD).
- Wichtige Spalten umfassen Kundensegment (Consumer, Corporate, Home Office), Produktkategorien und Unterkategorien (Möbel, Büromaterial, Technologie), Versandart, Bestelldatum, geografische Daten (50 US-Bundesstaaten, gruppiert in 4 Regionen), Verkaufsbetrag, Menge und Gewinnzahlen.
- Der von Kaggle bezogene Datensatz simuliert realistisch die Transaktionsdaten eines US-Supermarkts und ermöglicht so bedeutsame explorative Datenanalysen und Visualisierungen.Methodik und Schritte1. Datenaufbereitung und -bereinigung
- Laden und Analyse der Datensatzvariablen und -struktur.
- Sicherstellung der Datenqualität durch Validierung von Datumsbereichen, kategorialen Feldern und Konsistenz in Verkaufs-, Gewinn- und Kundensegmentdaten.2. Dashboard-Entwicklung in Power BI
Design mehrerer visueller Komponenten einschließlich:
- Tortendiagrammen zur Gewinnverteilung nach Region.
- Donut-Diagrammen zur Veranschaulichung von Gewinn nach Kundensegmenten und Produktkategorien.
- Balkendiagrammen zur Darstellung von Gewinn nach Produktunterkategorien.
- Liniendiagrammen zur Darstellung von Gewinntrends über Jahre und Quartale.
- Tabellenansichten für detaillierte Verkaufs- und Gewinnstatistiken.
- Slicern für dynamische Filterung (z. B. nach Bundesstaat).
-KPI-Karten zur Zusammenfassung von Verkaufs-, Gewinn- und Mengenkennzahlen.
- Fokus auf Interaktivität mit Filtern und Drill-Down-Funktionalität, um Nutzern die Analyse auf verschiedenen Detailebenen zu ermöglichen.3. Interaktivität und Nutzererlebnis
- Ermöglichung von Mouseover-Details, dynamischer Datenauswahl und Beobachtung der Auswirkung verschiedener Filter auf Gesamtkennzahlen.
- Erstellung eines klaren, logischen Layouts für intuitive Navigation durch verschiedene Datenaspekte.Wesentliche Erkenntnisse
1. Das Dashboard bietet einen umfassenden Geschäftsüberblick über Zeit, Produkt und Geografie und fördert datenbasierte Entscheidungen.
2. Die Visualisierung von Verkaufs- und Gewinnzahlen über verschiedene Diagrammtypen hebt Wachstumsbereiche und Problempunkte hervor (z. B. profitabelste Regionen oder verlustreiche Unterkategorien).
3. Kundensegmentdaten zeigen, wie unterschiedliche Kundentypen zur Umsatzentwicklung beitragen.
4. Die Nutzung interaktiver Filter unterstützt explorative Analysen und individuelle Berichtserstellung.Projekt-Nutzung1. Die Power BI-Berichtsdatei (.pbix) ist auf GitHub gehostet und kann von Nutzern unter Sales Profit PowerBI heruntergeladen werden.2. Für die vollständige Interaktivität sollten Nutzer die Datei mit der Power BI Desktop-Anwendung öffnen (kostenlos bei Microsoft erhältlich).3. Nach dem Öffnen können Nutzer alle Visualisierungen erkunden, mit Slicern interagieren und detaillierte Verkaufs- und Gewinnanalysen durchführen.4. Für Nutzer ohne Power BI Desktop zeigen bereitgestellte Screenshots die Hauptansichten des Dashboards als Übersicht der verfügbaren Einblicke.
PARSEC Racing – Student Formula Kart Projekt (2018–2019)
Ein kurzer Rückblick auf unsere End-to-End-Reise: ein Go-Kart von Grund auf zu bauen, uns auf nationale Wettbewerbe vorzubereiten und unter realen Rennwochen-Bedingungen zu lernen.
Mitbegründung von PARSEC Racing am Dayananda Sagar College of Engineering, Bengaluru, Indien, sowie Leitung eines studentischen Teams zur Entwicklung und zum Aufbau eines Go-Karts von Grund auf, zur Einwerbung von Industrie-Sponsoring und zur Teilnahme an nationalen Karting-Meisterschaften.Aufbau & Sponsoring (2018–2019)PARSEC Racing ist ein studentischer Automobil-Club, der 2018 am DSCE gegründet wurde. Wir stellten ein funktionsübergreifendes Team aus unserem Jahrgang zusammen und arbeiteten durchgängig End-to-End: Konzept, CAD/Design, Sponsorengewinnung, Koordination der Fertigung, Montage, Tests und Wettbewerbsreife. Meine Rolle umfasste Vice-Captain, Co-Designer sowie Teammanagement – mit Verantwortung sowohl für technische Entscheidungen als auch für die Umsetzungsplanung (Team, Zeitplan, Budget, Vendor-Follow-ups).
IKC 2019 — Indian Karting Championship (Kolhapur)Die Indian Karting Championship (IKC) 2019 war unser erster nationaler Wettbewerb und wurde an der Mohite Racing Academy in Kolhapur ausgetragen (14.–17. Feb. 2019). Wir erreichten den 15. Platz im Design-Event, bestanden die technischen Abnahmephasen und nutzten die Veranstaltung als Realitätscheck für Engineering-Zuverlässigkeit unter Wettbewerbsbedingungen. Den Endurance-Lauf konnten wir aufgrund eines Bremsversagens nicht abschließen – ein zentrales Learning für Designvalidierung, konsequente Testdisziplin und sicherheitskritische Prüfungen.
BFKCT 2019 — Bharat Formula Karting (Coimbatore)Bharat Formula Karting Season-2 (BFKCT) fand am Kari Motor Speedway in Coimbatore statt (28. Feb.–2. März 2019). In diesem Event belegten wir den 1. Platz in der Kategorie „Design Presentation“ und erhielten ein Preisgeld in Höhe von INR 15.000 (Best Virtual Design), was eine wesentliche Bestätigung unseres Engineering-Ansatzes und der Qualität unserer Dokumentation darstellte. Zudem absolvierten wir die dynamischen Disziplinen erfolgreich, was zeigte, dass das Kart nicht nur gut konstruiert, sondern auch track-ready war.
Go-Kart Launch — DSCE (4 Feb 2019)Das PARSEC Go-Kart wurde am 4. Feb. 2019 am DSCE im Fachbereich offiziell vorgestellt. An der Veranstaltung nahmen Sri. Naveen Soni (Vice President, TKM Pvt. Ltd.), Sri. Sailesh Shetty (Vice President, TKM Pvt. Ltd.) und Sri. Galiswamy (Secretary, DSI) teil. Dieser Meilenstein markierte den Übergang von einer studentischen Design-and-Build-Initiative zu einem wettbewerbsfähigen Fahrzeug, das der Hochschul- und Industrieleitung präsentiert wurde.
Downloads & LinksTeam Progress Report (PDF)
Während meines letzten Bachelorjahres hat unser Team das Fahrzeug erfolgreich fertiggestellt und am studentischen Wettbewerb teilgenommen. Parallel dazu führten wir strukturierte Rekrutierungen aus dem Junior-Jahrgang durch und schulten neue Mitglieder in zentralen Bereichen (Design, Fertigung, Betrieb/Operations und Dokumentation), um die langfristige Kontinuität des Teams sicherzustellen.Hinweis: Der Fortschrittsbericht ist ausschließlich in englischer Sprache verfügbar.Link zur Ansicht des 2020 bei der Universität eingereichten Fortschrittsberichts: Progress ReportOfficial College Website Article (Team Feature)
Ein offizieller Beitrag/Artikel über unser Team, veröffentlicht auf der Website der Hochschule, ist hier abrufbar.https://www.dsce.edu.in/automobile-engineering/student-clubs-auto
Portable e-Cycle — Bachelorarbeitsprojekt (2019–2020)
Die Portable e-Cycle ist ein umfassendes Abschlussprojekt des Bachelorstudiums, das am Dayananda Sagar College of Engineering (DSCE), Fachbereich Automobile Engineering, im Zeitraum 2019–2020 durchgeführt wurde.Ziel des Projekts war es, moderne Herausforderungen des urbanen Pendelns – Bewegungsmangel, Verkehrsüberlastung, Luftverschmutzung und Knappheit an Parkraum – durch die Entwicklung eines kompakten, leichten und umweltfreundlichen Fahrzeugs zu adressieren. Hierzu wurden ein mechanischer und ein elektrischer Antriebsstrang mit einem scherenartigen Faltmechanismus zur verbesserten Portabilität kombiniert.Als Projektleiter und CAD-Designer führte ich das Team durch den vollständigen Weg vom Konzept bis zum Prototypen: Problemdefinition, Literaturrecherche, Design-Iterationen mit Autodesk Fusion 360, Analyse der Werkstoffauswahl (Aluminium 6061, GFK/GFRP, Stahl AISI 4130, Carbonfaser), Finite-Elemente-Analyse (FEA) in ANSYS Workbench 19.2 sowie praktische Fertigung unter Einsatz von WIG-Schweißen (TIG).Erreichte DesignspezifikationenHöchstgeschwindigkeit 25km/h, Reichweite ca. 30km pro Ladung, Gesamtgewicht 16kg (Leergewicht), Zuladung 90kg, Abmessungen im gefalteten Zustand 0,75 × 0,42 × 1,15m.Der Rahmen wurde hinsichtlich statischer Strukturbelastungen, Ermüdungszyklen, modaler Dynamik, Verformung und Vergleichsspannung unter mehreren Materialkandidaten analysiert. Aluminium 6061 wurde als Rahmenmaterial gewählt, da es im Vergleich zu Alternativen das beste Verhältnis aus Sicherheitsfaktor (3.205), Gewicht (6.07 kg), Kosten und Fertigbarkeit bot (FEA zeigte: GFRP mit FOS 0.68 nicht sicher; Stahl mit 17.67 kg zu schwer; Carbonfaser wirtschaftlich nicht vertretbar).Wesentliche technische HighlightsScheren-Faltmechanismus (X-Muster statt linearem Falten, dadurch schnellere und einfachere Portabilität); 250W BLDC-Nabenmotor mit Li-Ion-Batterie (48V 4.8Ah oder 36V 6.8Ah); Komponentenbeschaffung und Kostenoptimierung (Gesamtbudget für die Fertigung ca. ₹22,070 INR); Design-FMEA mit Fokus auf Rahmendynamik, Kettenverschleiß, Motorüberlast, Batteriesicherheit und Integrität des Bremssystems; FEA-validierte Ermüdungslebensdauer (1,108 Zyklen, zufriedenstellend); Modalanalyse (8 Eigenfrequenzen im Bereich 106.86–559.53 Hz).Das E-Cycle fördert einen gesunden Pendelstil, reduziert den CO2 -Fußabdruck im Vergleich zu motorisiertem Individualverkehr, adressiert Parkraumrestriktionen in dicht besiedelten urbanen Gebieten und verbindet die Flexibilität von Pedalunterstützung mit elektrischem Komfort.Für eine detaillierte Projektpräsentation nutzen Sie bitte die folgenden Links (Hinweis: Präsentation und Bericht sind ausschließlich in englischer Sprache verfügbar):Project Presentation: Portable e-Cycle Presentation
Project Report: Portable e-Cycle Report